
关联规则挖掘在数字图书馆的应用

关联规则挖掘在数字图书馆的应用(含选题审批表,任务书,开题报告,毕业论文说明书10000字)
摘 要:高校图书馆作为高校师生的一个重要知识库,馆内藏书所涉及的领域非常广泛;图书馆每年购入新书,因此图书馆藏书量也在不断增多。师生们要在众多的书籍中找到自己需要的相关图书是一件非常困难的事情。因此,快速有效的优化藏书布局对师生的学习与研究显得尤为重要。本课题的目标就是运用数据挖掘中的关联规则方法,从读者的历史借阅数据中快速有效地挖掘出借阅书籍之间的关联信息,来帮助管理员优化藏书布局。
由于图书馆借阅数据每日有更新,数据库不断增大,并且根据需要的关联程序度不同,最小支持度也有变化。为了使图书摆放能够尽快适应师生介于需求,需要不断地更新挖掘结果。为此,本文提出运用MFIA-IU算法来解决数据库和最小支持度同时变化时的综合更新挖掘最大频繁项目集的问题,从而可避免每年对旧数据的重复挖掘。
关键词:数据挖掘;关联规则;最大频繁项目集; Apriori
Application of Association Rules Mining in Digital Library
Abstract:As an important knowledge base for teacher and students, university libraries cover a very wide field of books. Books are bought annually, so the number of books increases constantly. It is not pleasant for teacher and students to find books relevant to their own needs, so optimizing the layout of books quickly and effectively becomes more and more important for teacher and students. The dissertation is to mine the association information among the borrowed books from the history data quickly and effectively with association rules methods data mining.
[资料来源:http://doc163.com]
Due to the data of borrowed books is updated daily, the database becomes bigger continuously, and as the need of association degree is different, the minimal support is changed sometimes. In order to meet the need of teachers and students to borrow books as convenient as possible, it is necessary to update the mined results constantly. So the MFIA-IU algorithm is proposed to mine comprehensive updated maximum frequent sets when the database and the minimal support change simultaneously. thereby, the annually repeated mining of the old data is avoided.
Key words:Data mining; Association rule; Maximum frequent sets; Apriori
研究方案
研究目的:运用数据挖掘中的关联规则方法,从读者的历史借阅数据中快速有效地挖掘出借阅书籍之间的关联信息,来帮助管理员优化藏书布局。
研究内容:运用数据挖掘中的关联规则方法,从读者的历史借阅数据中快速有效地挖掘出借阅书籍之间的关联信息。
研究方法:运用关联规则的方法。包括数据的收集,数据的除“噪”等预处理,利用Apriori算法进行挖掘,最后得出结论。 [资料来源:Doc163.com]
预期结果:可以根据所掌握的数据得出解郁丸书籍之间的关联信息,方便管理员优化布局。
条件保障:数据真实有效。
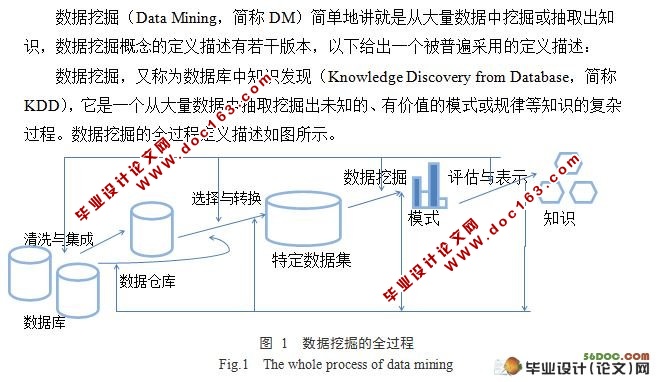
整个知识挖掘的主要步骤有:
(1)数据清洗,起作用就是清除数据噪声和与挖掘主题明显无关的数据。
(2)数据集成,其作用就是将来自多数据源中的相关数据组合到一起。
(3)数据转换,其作用就是将数据转换为易于进行数据挖掘的数据存储形式。
(4)数据挖掘,他是知识挖掘的一个基本步骤,其作用就是利用智能方法挖掘数据模式或规律知识。
(5)模式评估,其作用就是根据一定评估标准从挖掘结果筛选出有意义的模式知识。
(6)知识表示,其作用就是利用可视化和知识表达技术,向用户展示所挖掘出的相关知识。
目 录
摘 要 1
关键词 1
1 前言 2
2 数据挖掘概述 2
3 关联规则 3
3.1 关联规则基本理论 3
3.2 关联规则中的基本概念 3
3.2.1 项与项集 3
3.2.2 事务 3
3.2.3 项集的频率 4
3.2.4 关联规则 4
3.2.5 项集的支持度和置信度 4 [版权所有:http://DOC163.com]
3.2.6 最小支持度与最小置信度 4
3.2.7 频繁项目集 4
3.2.8 相关分析 4
3.2.9 强规则 5
3.3 关联规则挖掘的常用算法 5
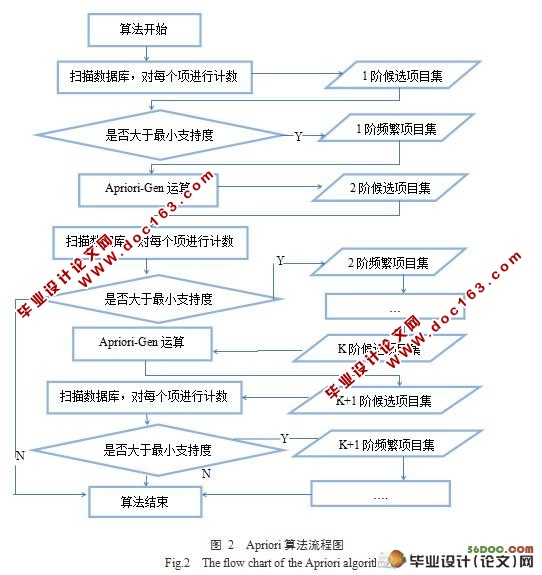
3.3.1 Apriori算法 5
3.4 Apriori算法的C语言实现 7
3.5 关联规则挖掘在国内外的应用 10
4 关联规则挖掘在图书馆的应用 11
4.1 数据选取 12
4.2 图书馆借阅数据的预处理 13
4.3 关联规则挖掘的过程 15
4.4 关联规则挖掘结果 17
5 结论 17
参考文献 17
致 谢 19 [资料来源:http://Doc163.com]