
关联规则在农业信息挖掘中的应用研究(附答辩)
关联规则在农业信息挖掘中的应用研究(附答辩)(含选题审批表,任务书,开题报告,毕业论文说明书16000字,答辩记录)
摘 要:随着农业数据的快速积累和增长,如何利用海量的农业数据以获取科学的农业知识、规律和决策支持信息成为非常重要的课题。首先,本文简述数据挖掘技术在农业信息挖掘中的概况;然后,分析了关联规则的原理和作用,深入分析Apriori、FP-Tree等算法的特点;最后,应用到挖掘农业信息与农业产值之间的关联关系,指导农业生产并为农业生产提供正确科学依据及可靠的决策支持。
关键词:关联规则;Apriori算法;农业信息挖掘
Research on Association Rules Application in Agricultural Information Mining
Abstract:As agriculture data rapidly accumulating and growth, how to use the mass data to obtain scientific agriculture agricultural knowledge, regularity and decision support information becomes very important topic. First of all, this paper briefly describes the data mining technology in the situation of agricultural information mining. Then, the paper analyzes the principle and function of association rules, in-depth analysis of FP-Apriori, algorithms' characteristics such as Tree. Finally, it applies these algorithms to excavate the agriculture information and the relationship between agricultural output, guide agricultural production and to provide the correct for agricultural production and reliable scientific basis for decision support.
[资料来源:www.doc163.com]
Keywords:Association rules; Apriori algorithms; Agricultural information mining
2.4 数据挖掘的功能
数据挖掘功能用于指定数据挖掘任务中要找的模式类型。数据挖掘任务一般可分而两类:描述和预测。描述性挖掘任务刻画数据库中数据的一般属性;预测型挖掘任务在当前数据上进行推断,以进行预测。
在某种情况下,用户不知道什么类型的模式是有趣的,因此可能想并行的搜索多种不同的模式。这就需要数据挖掘系统能够挖掘多种类型的模式,一适应不同的用户需求或不同的应用。此外,数据挖掘系统应当能够发现各种粒度(即不同的抽象层)的模式。数据挖掘系统应当应允用户给出提示,指导或聚集有趣模式的搜索。数据挖掘功能以及它们可以发现的模式类型介绍如下。
2.4.1 关联分析
关联分析(Association Analysis)用于发现关联规则,关联知识(Association)反映一个事件和其他事件之间的依赖或关联。关联分析的目的就是找出数据库中隐藏的关联信息。关联可分为简单关联、时序关联、因果关联、数量关联等。
2.4.2 自动预测趋势的行为
数据挖掘自动在大型数据库中寻找预测性信息,以往需要进行大量手工分析的问题如今可以迅速直接由数据本身得出结论。一个典型的例子就是市场预测问题,数据挖掘使用过去有关促销的数据来寻找未来投资中回报最大的用户,其他可预测问题包括预测破产以及认为对指定事件最可能做出反映的群体。 [资料来源:Doc163.com]
2.4.3 分类和预测
分类(Classification)和预测(Prediction)是两种数据分析形式,可以用于提取描述重要数据类的模型或预测未来的数据趋势。数据分类是一个两步的过程,第一步,建立一个模型,描述给定的数据集,通过分析由属性描述的数据远组来构造模型,这部分的算法有:决策树(Decision Tree)、贝叶斯分类算法(Bayesian Classification)、后向传播算法(Back Propagation)、K-最近邻近分类算法(K-Nearest Neighbor Classifiers)、基于案例的推理(Case-based Reasoning)、遗传算法(Genetic Algorithms)、粗糙集算法(Rough Set Algorithms)、模糊集算法(Fuzzy Set Approaches)、神经网络算法等(Neural Networks)等。第二步,使用数据模型进行分类[5]。
分类和预测的区别是:用预测法预测分类标号(离散值)为分类,用预测法预测连续值(例如使用回归方法)为预测。分类和预测具有广泛的应用,包括信誉证实、医疗诊断、性能预测和选择购物等。
2.4.4 聚类分析
聚类(Clustering)是将数据对象分组成为多个类型或簇,在同一簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。与分类和预测不同,聚类操作要划分的类是事先未知的,类的形成是数据驱动的,属于一种无指导的学习方法。主要的聚类算法可以划分为如下几类:划分方法(Partitioning Method)、层次的方法(Hierarchical Method)、基于密度的方法(Density-based Method)、基于网格的方法(Grid-based Method)、基于模式的方法(Model-based Method)。聚类分析已经广泛应用于许多方面包括模式识别,数据分析,图象处理,以及市场研究等。 [资料来源:http://doc163.com]
2.4.5 孤立点分析
数据库中可能包含一些数据对象,它们与数据的一般行为或模型不一致。这些数据对象对称为孤立点(Outlier),大部分数据挖掘方法将孤立点视为噪声或异常而丢失。然而在一些应用中(如欺骗检测),孤立点事件可能比较正常出现的事件更有趣,孤立点数据分析称作孤立点挖掘。基于计算机的孤立点探测方法分为三类:基与统计的孤立点检测(Statistics-based Outlier Detection)、基于距离的孤立点检测(Distance-based Outlier Detecion)、基于偏离的孤立点检测(Deviation-base Outlier detection)。孤立点分析可以发现信用卡欺骗。通过检测一个给定帐号与正常的付费相比,以付款数额特别大来发现信用卡欺骗性使同。孤立点值还可以通过购物地点和类型,或购物频率来检测。
2.4.6 演变分析
数据演变分析(Evolution Analysis)描述行为随时间变化的对象的规律或趋势,并对其建模。尽管这种分析可能包含时间相关数据的特征化、区分、关联、分类或聚类,这类分析的不同特点包含时间序列数据分析、序列或周期模式匹配和基于类似性的数据分析[6]。
[资料来源:Doc163.com]

目 录
摘要 1
关键词 1
1 前言 2
2 数据挖掘概述 2
2.1 数据挖掘的简介 2
2.2 数据挖掘的研究现状 2
2.3 数据挖掘的过程 3
2.4 数据挖掘的功能 4
2.4.1 关联分析 4
2.4.2 自动预测趋势的行为 4
2.4.3 分类和预测 4
[来源:http://Doc163.com]
2.4.4 聚类分析 5
2.4.5 孤立点分析 5
2.4.6 演变分析 5
3 关联规则的概述 5
3.1 关联规则的定义 6
3.2 关联规则属性的四个参数 6
3.2.1 支持度(Support) 6
3.2.2 可信度(Confidence) 6
3.2.3 期望可信度(Expected Confidence) 7
3.2.4 作用度(Lift) 7
3.3 关联规则的分类 7
3.4 关联规则的挖掘步骤 8
4 关联规则的挖掘算法 8
4.1 布尔型关联规则的挖掘 8
4.2 多层关联规则的挖掘 8
4.3 多维关联规则的挖掘 8
5 算法介绍及实现 9
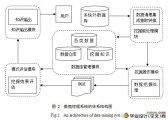
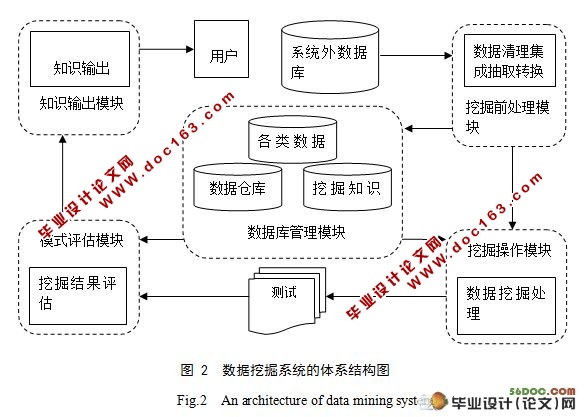
5.1 数据挖掘的体系结构 9
5.1.1 数据库管理模块与挖掘前处理模块 9 [版权所有:http://DOC163.com]
5.1.2 模式评估模块、知识输出模块以及挖掘操作模块 9
5.2 算法介绍及实现 10
5.2.1 Apriori算法简介 10
5.2.2 Apriori算法的组成 10
5.2.3 Apriori算法的实现 11
5.2.4 FP-tree算法简介 15
5.2.5 挖掘FP-tree的主要步骤 16
5.2.6 FP-tree算法与Apriori算法的比较 19
6 基于农业普查数据库的数据挖掘系统 20
6.1 面临的问题 20
6.2 解决方法 21
6.3 数据挖掘系统 21
6.4 数据预处理 22
6.5 实际应用 23
7 结论 25
参考文献 26
致 谢 27
[资料来源:Doc163.com]