
基于Web日志挖掘用户的浏览兴趣路径(附答辩)
基于Web日志挖掘用户的浏览兴趣路径(附答辩)(含选题审批表,任务书,开题报告,中期检查表,毕业论文说明书12000字,答辩记录)
摘 要:Web日志中包含了大量的用户浏览信息,如何有效地从其中挖掘出用户浏览兴趣模式是一个重要的研究课题。首先,本文分析Web日志挖掘的研究背景和研究意义,并对国内外相关研究进行调研;其次,概述Web日志挖掘的一般步骤,挖掘算法和模式分析点;最后分析基于Web日志挖掘用户的浏览兴趣路径的主要技术,并结合相关网站进行了具体实验。
关键词:Web日志挖掘 关键字 浏览兴趣。
Discovering Preferred Browsing Paths From Web Log
Abstract:Web log contains a large number of user browsing information, how to discover preferred browsing paths from Web log is an important research topic. Firstly, this paper analyzes the Web log mining research background and the significance, and the related researches both at home and abroad research. Secondly, it summarizes the general steps of Web log mining, mining algorithm and pattern analyzes. Finally, it analyzes the key technologies of discover preferred browsing paths from Web log and makes experiment with the related sites.
[版权所有:http://DOC163.com]
Keywords:Web log mining ;Keywords; Browse interest.
Web日志挖掘基本概述
2.1 Web日志挖掘定义
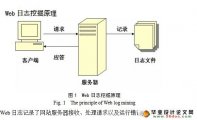
所谓Web日志,是指在服务器上有关Web访问的各种日志文件,包括访问日志、引用日志,代理日志,错误日志等文件,这些文件里包含了大量的用户访问信息,如用户的IP地址、所访问的URL、访问日期和时间,访问方法 (GET或POST)、访问结果(成功、失败、错误、访问的信息大小)等。
研究目的
掌握基于Web日志挖掘用户的浏览兴趣路径的基本原理,实现其基本功能。
研究内容
(1) Web日志挖掘定义和原理;
(2) 预处理数据,利用算法进行计算;
(3) 调研相关网站;
(4) 具体实验说明。
研究方法
(1)讨论法:同老师和同学进行讨论。
(2)文献资料法:就Web日志挖掘查阅国内外相关的相关资料和书籍。
(3)实践法:通过实践挖掘Web日志用户的浏览兴趣路径。
条件保障
图书馆和互联网有丰富的文献资料可阅读。
[资料来源:http://www.doc163.com]

目 录
摘要 1
关键词 1
1 绪论 1
1.1 课题的研究背景及意义 1
1.2 Web日志挖掘国内外研究现状 2
1.2.1 国外研究现状 2
1.2.2 国内研究现状 2
1.3现存问题 2
2 Web日志挖掘基本概述 3
2.1 Web日志挖掘定义 3
2.2 Web日志挖掘原理 5
2.3 Web日志挖掘应用 5
2.4 Web日志挖掘难点 6
3 Web日志挖掘过程 7
3.1 数据预处理 7
3.1.1 数据转换 7
3.1.2 数据清理 7
3.1.3 用户识别 8
3.1.4 会话识别 8
3.1.5 路径补充 8
3.2 挖掘算法研究 9
3.2.1 关联规则挖掘 9
3.2.2 序列模式挖掘 9
3.2.3 聚类分析 9
3.3 模式分析 10
4 Web日志挖掘的具体实现 10
4.1 Web用户访问模式 10
4.2 Web用户访问挖掘算法 10
4.2.1 算法基本定义 11
5 Web日志挖掘具体应用和实验 12
5.1 日志预处理 13
5.2 单个客户访问兴趣分析 14
5.3 群体客户访问兴趣分析 16
6 结论 16
参考文献 17
致 谢 18