
基于DTW算法实现对英文字母的语音识别
基于DTW算法实现对英文字母的语音识别(任务书,开题报告,论文14700字)
摘要
语音是人类交流的最为重要的工具,绝大多数情况下人们采用语音的方式表达自己的目的。随着科技的不断发展,人们已经不单纯满足于只用语音进行交流,更希望于我们可以用语音指令来控制各种机器,让这些机器可以明白我们的指令。因此,需要我们了解语音识别技术的原理并将其应用到各个方面。
目前对于孤立词的识别大多数采用的是动态时间规整算法(DTW)。其核心的思想是将参考模板和测试语音信号进行模式匹配。因其在适用于孤立词识别时相对其他算法具有更加简单,识别正确率更加高的优点。本文在基于DTW算法的基础上实现对单个英文字母的识别,主要做了以下的研究工作:
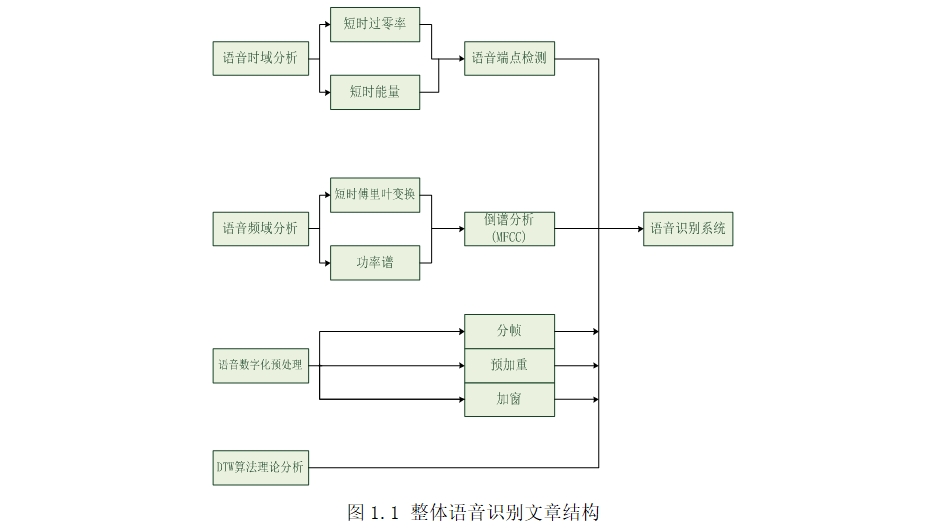
利用matlab编写代码完成对输入语音的预处理,其中包括分帧、预加重、利用短时能量和短时过零率进行端点检测。
DTW算法则由其计算累积距离的原理并利用matlab代码实现。
特征参数采用梅尔倒谱系数(MFCC)。目前MFCC是被采用最多的特征参数,因其可以充分表现人耳的听觉特性,并且在较低的信噪比的情况下也能实现较好的识别功能。
在识别模块先计算参考模式库中的全部模板的特征矢量,然后计算测试部分的音频的特征向量,之后利用DTW算法将测试部分特征向量和参考模式库中的特征向量逐一计算累积距离,选择累积距离最小的那个作为最后的识别结果。
[版权所有:http://DOC163.com]
最后尝试对带有噪音的语音进行增强之后进行识别。
关键字:语音识别、预处理、动态时间规整(DTW)、梅尔倒谱系数(MFCC)
Abstract
Human use the voice as the most important tool to communicate with others. And they also use voice to express their purpose in most cases.With the continuous development of science and technology, people are not only satisfied with using only voice to communicate, but also hope that we can use voice commands to control various machines so that these machines can understand our instructions. This requires applying the principles and techniques of speech recognition to all aspects.
At present, most of the algorithms adopted for the recognition of isolated words are dynamic time warping algorithms (DTW), and the core method is to use pattern matching. Because it is relatively simple compared to other algorithms when it is applied to isolated word recognition, the recognition accuracy rate is higher. In this paper, based on the DTW algorithm to achieve the recognition of a single English alphabet, the main research work done in the following: [来源:http://Doc163.com]
The use of matlab to write code to complete the input speech preprocessing, including frame, pre-emphasis, using short-term energy andshort-term zero-crossing rate endpoint detection.
DTW algorithm is calculated by the principle of its cumulative distance and using matlab code.
We choose the Mel Cepstrum coefficient (MFCC) as the feature parameter extraction.At present, MFCC is the most used characteristic parameter, because it can fully express the auditory characteristics of the human ear. Besides,it can also achieve better recognition function in the case of a lower SNR.
Using the characteristic parameters in the reference pattern library and the audio feature parameters of the test part, then the DTW algorithm is used to compare the cumulative distance of the reference pattern library with the cumulative distance of the test part, and the smallest distance is the recognition result.
Finally tried to identify the voice with noise after enhancement.
Keywords: Speech Recognition, Preprocessing, Dynamic Time Warping (DTW), Mel Cepstrum Coefficient (MFCC)
[来源:http://www.doc163.com]

目录
摘要 I
Abstract II
第1章 绪论 1
1.1 课题研究的背景及意义 1
1.2 DTW算法的研究现状 2
1.3 论文的主要工作及内容安排 3
第2章 语音信号的分析以及特征参数的提取 4
2.1语音信号的时域分析 4
2.1.1语音分帧 4
2.1.2 短时能量分析 5
2.1.3 短时过零率分析 5
2.1.4 短时相关分析 6 [资料来源:https://www.doc163.com]
2.2 语音信号的频域分析 6
2.2.1 短时傅里叶变换 6
2.2.2功率谱 6
2.3 语音处理阶段的关键技术 7
2.3.1 语音端点检测 7
2.3.2 语音信号的数字化和预处理 7
2.4 特征参数提取 8
2.4.1 语音信号倒谱分析 8
2.4.2 梅尔倒谱系数 8
2.6 本章总结 12
第3章 算法理论 13
3.1 DTW算法 13
3.1.1 DTW算法原理 13
3.1.2 DTW算法的训练 15
3.2 利用DTW的语音识别流程 15
3.3 DTW算法HMM以及神经网络的简单比较 15
3.4 本章小结 16
第4章 语音识别系统的设计与实验 17
4.1 语音识别系统的总体流程图 17
4.1.1 语音录入与分帧加窗 17
4.1.2 计算语音信号的短时过零率 19 [资料来源:www.doc163.com]
4.1.3 计算语音信号的短时能量 19
4.1.4 语音信号端点检测 20
4.1.5 降噪处理 22
4.1.6 特征参数提取 24
4.1.7 DTW算法实验 24
4.2 本章小结 27
第5章 总结与展望 29
5.1 总结 29
5.2 展望 29
参考文献 31
致谢 33
[资料来源:https://www.doc163.com]